


How to improve how fast desktops/laptops/phones execute code: SIMD/SMP/GPGPU/TPU

[This post allows all uses.] [Version of this post is 7fd575c, view `preview` branch for the most new version.]
Intro
Since around the year 2002, the physical CMOS limits of transistors have meant that the ghz (gigahertz) of CPU's can not improve, and thus multicore (SMP, also known as Symmetric Multiprocessing) / SIMD (also known as Single Instruct Multiple Data) is required for throughput to continue to improve.
To improve:
Switch to CPU's with more cores and new SIMD opcodes to use.
Switch to CPU's / GPU's / RAM which uses more small transistors (lower "nm" values), as those have more compute units plus reduce power use.
For closed source program use:
Search for new versions of programs, which use OpenMP (or which use other such tools which produce SMP & SIMD code flows).
Search for versions which list the newest CPU which is not more new than the CPU in use.
Microsoft Windows has WoW64 to execute programs as x32 or x64 based on your current CPU.
Linux's equivalent is Multiarch (which is similar to Microsoft Windows’ WoW64.
If the CPU in use supports 64-bit execution, choose program versions which list "AMD64", "Intel64", "x86_64", "aarch64", or "Arm64"; those will all use SIMD opcodes.
For open source (FLOSS) programs use:
Recompile the source code with
--march=native(insert into compiler flags) to produce the newest SIMD code which the currrent CPU can use.MSVC (MicroSoft Visual Compiler) has auto-vectorization (produces executables which use SIMD opcodes on compatible CPUs).
GCC (GNU Compiler Collection) also has auto-vectorization.
Clang / LLVM (Low-Level Virtual Machine) also has auto-vectorization.
Recompile the source code with
--openmp(insert into compiler flags), which enables#pragma omp <command>(where<command>is the specific subset of OpenMP to use, such asparallelorsimd).Improve source code: if the source code does not have SIMD directives, ensure the code is amenable (does not have inter-element dependencies of tensors) (remember to consider how the compiler's Abstract syntax tree differs from human-readable source code) + insert
#pragma omp simdabove amenable loops, or use intrinsic functions (which allow manual insertion of SIMD opcodes).Improve Source code: if the source code does not have directives for multiple CPU core use, insert
#pragma ompdirectives which instruct the compiler to prefer multiple core use above the start of loops which most suit multiple core use:Loops which do not have dependencies on the previous iteration of the loop.
Loops total whose total iterations count can absorb (ammeliorate) thread (or process) startup costs. Unless the architecture is similar to GPUs (which have minimal thread startup costs), this requires iteration counts in the thousands (or more numerous).
Disable stylistic features (such as shadows or animations) — unless your workflow has use for those (such as school classes about graphics do) — and measure (to determine if the resource use goes down or if responsiveness improves; if so, put a note to disable those in the future).
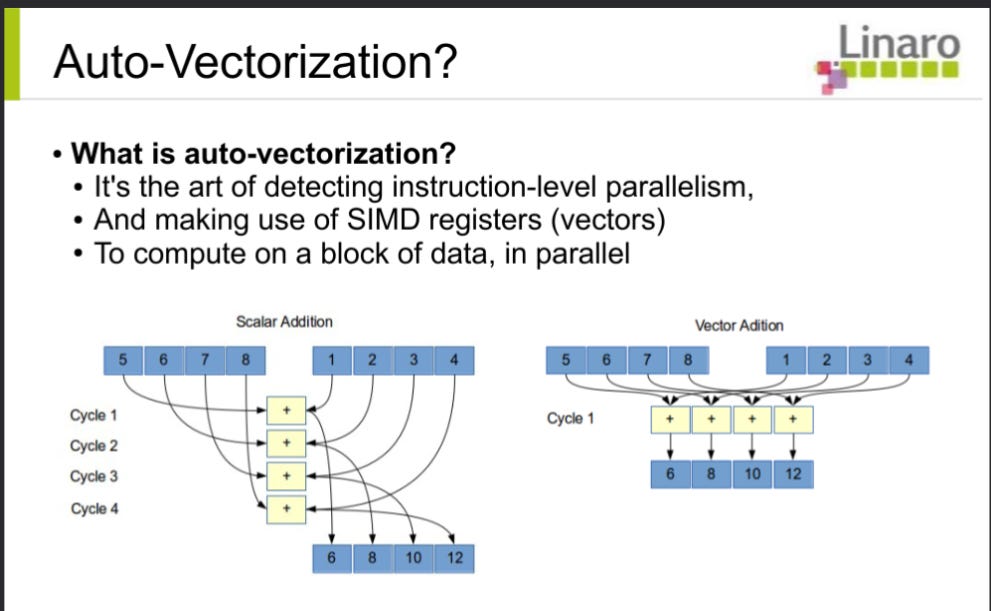
C++'s "syntactic sugar" reduces source code sizes (due to classes, templates, and the STL, which allow more source code reuse), plus are more abstract, which gives compilers more room to implement the source code through SMP or SIMD opcodes (uops):
https://stackoverflow.com/questions/13676172/optimization-expectations-in-the-stl
https://devblogs.microsoft.com/cppblog/algorithm-optimizations-advanced-stl-part-2/
SIMD (Single Instruction Multiple Data)
SIMD-compatible CPUs:
All 64-bit Intel / AMD CPUs allow SSE2 (Streaming SIMD Extensions 2).
Most aarch64 / Arm64 CPUs allow NEON.
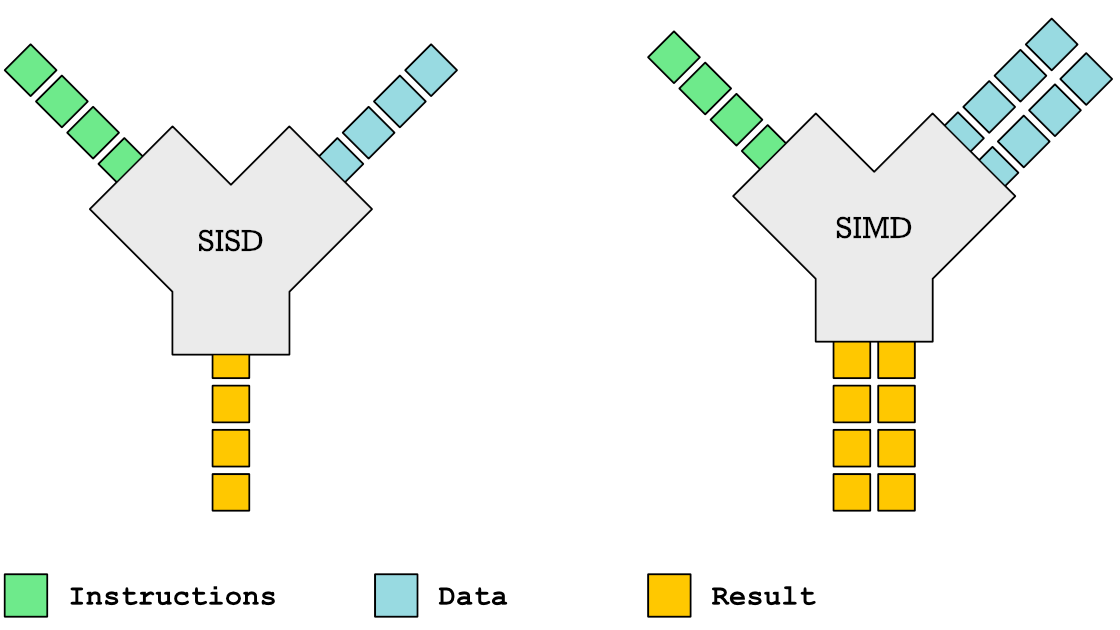
SIMD resources:
Common SIMD instruction sets include SSE2 (Streaming SIMD Extensions 2), SSE4.2 and AVX2 (Advanced Vector Extensions 2[2].
Newer Intel64 / AMD64 CPUs allow AVX-512 (which is one of the newest SIMD instruction sets) opcodes to do operations on tensors (vectors, arrays or matrices) of 16 packed 32-bit
integers (orfloats) at once (which uses just 1 microinstruction-cycle -- 1 uop -- on the CPU). AVX-512 allows expansion to AVX-1024 (opcodes which compute packs of 32).Newest CPUs allow AMX (Advanced Matrix Extensions ) opcodes, which compute 1024 half-float operations per uop.
AMX use is similar to TPU use, but is through (new) opcodes on normal CPUs (opposed to dedicated ASICs, which constitute TPUs).
Comparison of how AVX2 versus AVX-512 versus AMX intrinsic functions implement 4x4 tensor transpose. Digital Assistant's are not suitable to produce most code (such as code which involves high-level control flow or user interactions), but are suitable to produce specific compute kernels (such as tensor transpose).
Intel Performance Primitives (for Microsoft Windows and Linux / Unix) includes multiple SIMD versions of compute kernels, and uses uses
cpuidto do dynamic code dispatch to the most new instruction set compatible with the current CPU (similar to GCC's "function multi-versioning", but specific to x86 CPUs).Solaris also uses
cpuidto choose the most performant code path (opcodes) which your CPU allows and has protocols which allow users to force use of advanced opcoodes.
GCC / LLVM / Clang accept march=native to recompile programs to use the most advanced opcodes.
Linux / Unix allows you to recompile the whole OS, to use the newest instruction set opcodes (uops) compatible with the current CPU.
ArchLinux was produced to reduce the effort to recompile all packages, with custom flags (the Linux ecosystem calls programs "packages") to use your CPU’s most suitable opcodes (uops).
New versions of GCC / LLVM / Clang have flags to produce multiple code SIMD versions of compute kernels and use
cpuidto choose the path which uses the newest opcodes (uops) compatible with the current CPU, similar to Intel Performance Primitives (except not specific to x86 CPUs). GCC's version of this is "function multi-versioning"
GPGPUs (General Purpose Graphics Processor Units)
Auto-parallelization produces threaded (multicore) code (searches for code with lots of loops, distributes those loads across all local CPUs or GPUs):
https://www.intel.com/content/www/us/en/developer/articles/technical/automatic-parallelization-with-intel-compilers.html; “Adding the
-Qparallel(Windows*) or-parallel(Linux* or macOS*) option to the compile command is the only action required of the programmer. However, successful parallelization is subject to certain conditions”https://gcc.gnu.org/wiki/AutoParInGCC (
gccorg++) "You can trigger it by 2 flags-floop-parallelize-all -ftree-parallelize-loops=4"https://polly.llvm.org/docs/UsingPollyWithClang.html “To automatically detect parallel loops and generate OpenMP code for them you also need to add
-mllvm -polly-parallel -lgompto yourCFLAGS.clang -O3 -mllvm -polly -mllvm -polly-parallel -lgomp file.c"https://link.springer.com/chapter/10.1007/978-3-030-64616-5_38 "LLVM Based Parallelization of C Programs for GPU"
https://stackoverflow.com/questions/41553533/auto-parallelization-of-simple-do-loop-memory-reference-too-complex (distributes Fortran tasks).
TPUs (Tensor Processor Units)
The subset of ASICs (Application-Specific Integrated Circuits) known as TPUs are processors which are specific to the tensor workloads which the SIMD section mentions, such as AMX's tensor transpose uop.
Most TPUs were limited to specific commercial users, but new consumer computers (and some smartphones) include TPUs.
Most smartphone TPUs sacrifice integer (and float) precision, to reduce die area (square inches) and power use (watts), which limits those to inference use. It is possible that future chips will use some new fused architecture which allows training (back-propagation) + inference (forward-propagation) from shared transistors..
Google's Edge TPUs can does inference through TensorFlow. Coral says the original Edge TPU processes 4 quarter-precision teraOPS (trillion opcodes per second) with 2W power use
The Google Pixel 2's Pixel Visual Core... is an edgeTPU (mobile chip which does inference through TensorFlow)).
The Google Pixel 4's Pixel Neural Core... is also an edgeTPU (can also do inference through TensorFlow). Pixel Neural Core uses the original Edge TPU
The Google Pixel 6's Google Tensor TPU is an edgeTPU which Claude-3-Haiku says can process 5.2 teraFLOPS with average 6-watt power use (if average load is 62%)
The iPhone X's Apple Neural Engine can do 0.6 half-precision teraFLOPS. The iPhonoe 13 Pro's 5th-gen Apple Neural Engine (part of "A15") can do 15.8 (unspecified precision) teraFLOPS, but is limited to Core ML.
TensorFlow Lite can now use smartphone TPUs. Standard TensorFlow can use desktop / laptop / server TPUs.
Synopsis + related posts
TensorFlow's MapReduce (https://www.tensorflow.org/federated/api_docs/python/tff/backends/mapreduce) distributes loads across clouds of CPUs / GPGPUs / TPUs. The sort of SW (programs) which improve the most through use of MapReduce is artificial neural tissue (which can distribute execution through billions of processes), such as:
[Preview] How to use FLOSS systems to produce autonomous Arduino/Elegoo tools
![[Preview] How to use FLOSS systems to produce autonomous Arduino/Elegoo tools](https://substackcdn.com/image/fetch/w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa8161c21-de58-4e83-8456-e3b4374b6aef_2245x896.png)
[This post from SubStack allows all uses.]
Virus analysis tools should use local static analysis + sandboxes + artificial CNS (central nervous systems) to secure computers.

[This post allows all uses.] For Table of Contents, view on GitHub.
![[Preview] Have computers do most of central nervous system (such as thalamus, auditory cortex, visual cortices, homunculus)](https://substackcdn.com/image/fetch/w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F701d2233-f8f9-46da-9342-d42fb2116cf1_280x180.jpeg)
Albatross performs lots of neural processes per neural volume versus humans, howto base artificial neural networks off of albatross

With (or without) attributions, all posts allow all (re)uses. Simple artifical neural networks: (FLOSS/unlicensed) https://github.com/topics/artificial-neural-network https://learn.microsoft.com/en-us/archive/msdn-magazine/2019/april/artificially-intelligent-how-do-neural-networks-learn
Program general purpose robots as autonomous tools through calculus. Possible to produce general purpose robos as autonomous tools, + close-to-human consciousness

With (or without) attributions, all posts allow all (re)uses. Use DFS/BFS/IDDFS to run close to continuous functions as calculus General artificial intelligence allows autonomous robots to produce complex goods Possible to produce general purpose robos as autonomous tools, + close-to-human consciousness. Kuka/Facteon/Fanuc can't work outdoors or as carpe…